Statice's synthetic data technology is now part of Anonos Data Embassy, the award-winning data security and privacy solution.
.png)

Pseudonymization and anonymization both play an important role in data processing, data security, and data access processes since the General Data Protection Regulation (GDPR) came into force. It’s because data protection methods are necessary to comply with regulations while being able to use data for business projects.
These data protection methods fall under different categories according to the GDPR. If you want to use sensitive data in projects while meeting all data protection obligations, make sure you understand all the nuances of those methods.
In this article, we are going to focus on personal data processing within organizations so you get a grasp of the topic. You’ll learn:
Disclaimer: Remember, this article is an educational one. It’s not legal advice and should not be treated as such.
According to the National Institute of Standards and Technology (NIST):
Personally Identifiable Information (PII): Any representation of information that permits the identity of an individual to whom the information applies to be reasonably inferred by either direct or indirect means. All PII is Personal Data, but not all Personal Data is PII.
PII can be any information that lets you trace and identify an individual. So this can be full name, address, passport number, email, credit card numbers, date of birth, telephone number, login details, and many more.
Personal Identifiers (PID) are a subset of PII data elements that identify a unique individual and can permit another person to “assume” an individual's identity without their knowledge or consent.
Personal Data is any information relating to the individual that could re-identify them, including direct identifiers, indirect identifiers, attributes and other characteristics that could be used to relink to identity, including information related to a person’s physical, physiological, mental, economic, cultural or social identity. Personal Data is a much broader category than PII or PID.
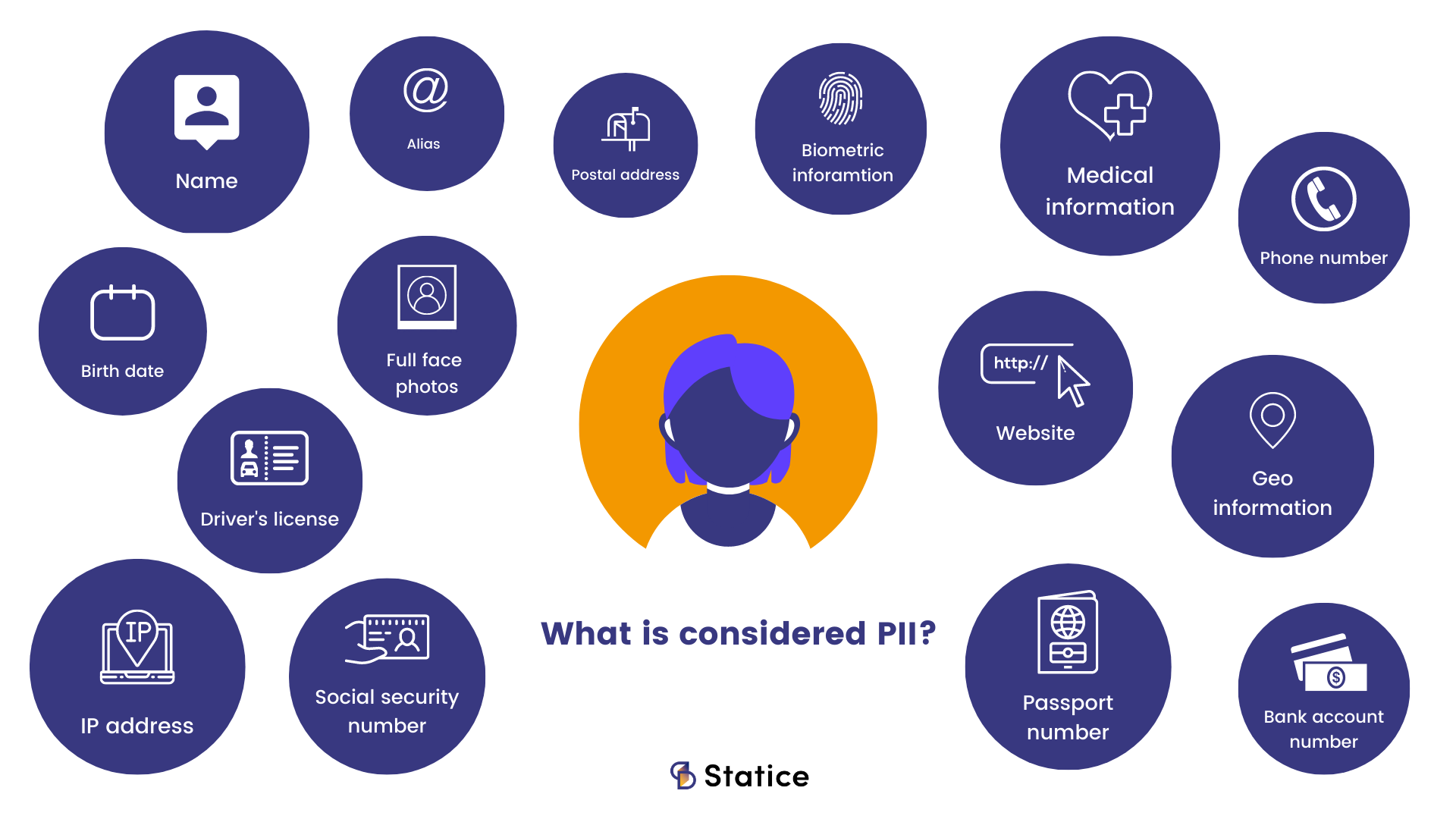
Now that you understand what PII, PID, and Personal Data are, let’s jump to the topic of anonymization and pseudonymization.
Statutory pseudonymization is a standard in the GDPR that needs to be met if you want to process personal data and use it in line with GDPR requirements.
Let’s take a look at how the GDPR defines pseudonymization.
According to art. 4 GDPR:
‘pseudonymisation’ means the processing of personal data in such a manner that the personal data can no longer be attributed to a specific data subject (individual person who can be identified) without the use of additional information, provided that such additional information is kept separately and is subject to technical and organizational measures to ensure that the personal data are not attributed to an identified or identifiable natural person;
In other words, the data controller must de-link identity from the information for processing, and store the re-linking information separately and securely so that the two pieces cannot be put back together unless someone is authorized to do so. This way, the person cannot be identified from the statutorily pseudonymized dataset.
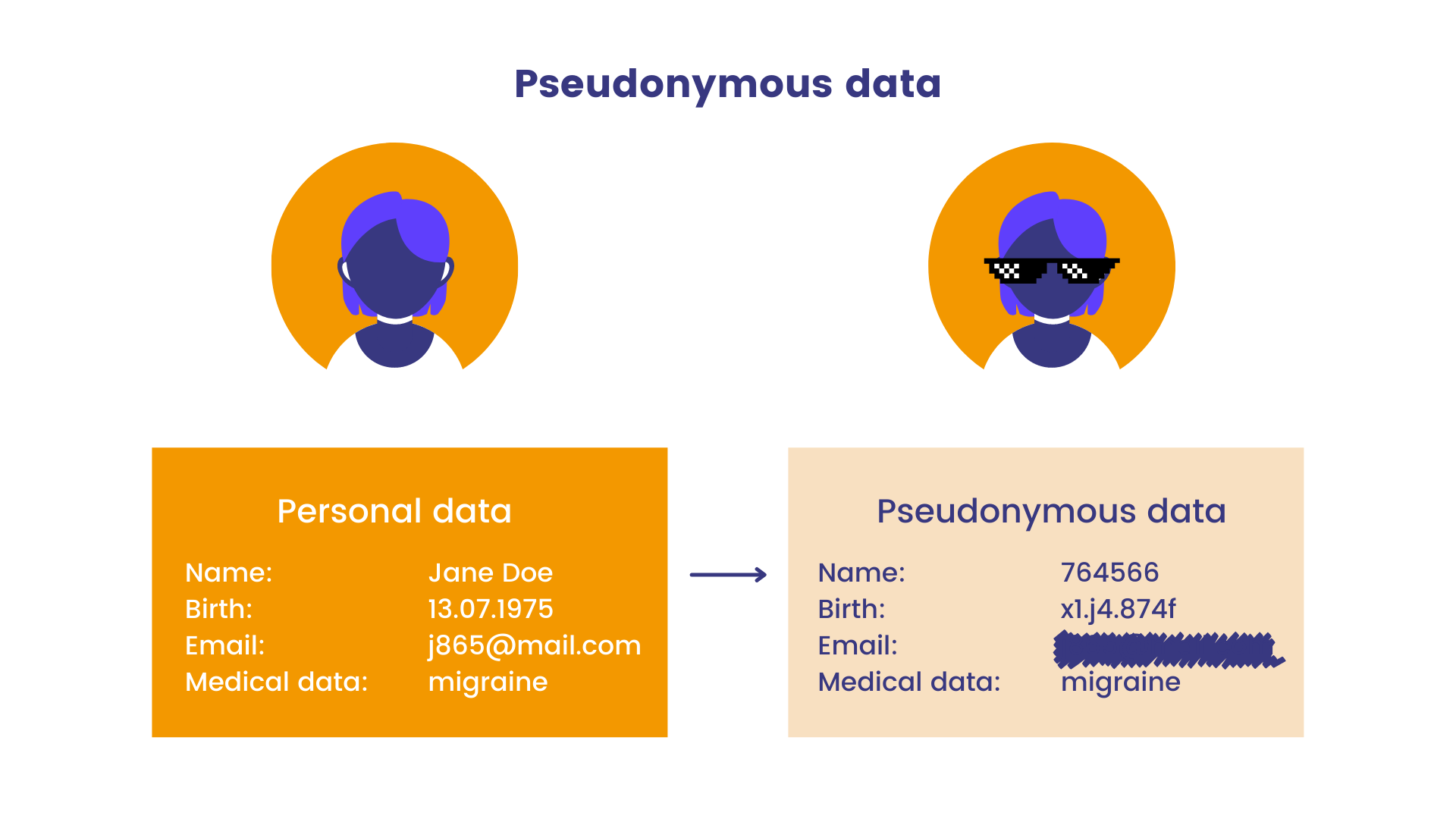
It is important to note that under the General Data Protection Regulation, pseudonymized data is still considered personal data.
You should still comply with all GDPR requirements for personal data protection (purpose limitation, storage limitation, integrity and confidentiality, etc.).
And if you want to process data for analytics purposes, data anonymization can also be used to safeguard personal data privacy and derive insights from it.
In contrast to pseudonymization, data anonymization is the process of irreversible transformation of personal data. The goal of anonymizing data is not only to remove personal identifiers but also to ensure that it’s impossible to determine who an individual is from the rest of the data, and for this process to be permanent
Let’s see how the GDPR defines data anonymization.
According to recital 26 EU GDPR:
The principles of data protection should therefore not apply to anonymous information, namely, information that does not relate to an identified or identifiable natural person or to personal data rendered anonymous in such a manner that the data subject is not or no longer identifiable.
This regulation does not, therefore, concern the processing of such anonymous information, including for statistical or research purposes.
Since anonymous data doesn’t contain PII and the process is irreversible, it is no longer subject to the GDPR.
Anonymizing data can have many business advantages for you. Truly anonymous data:
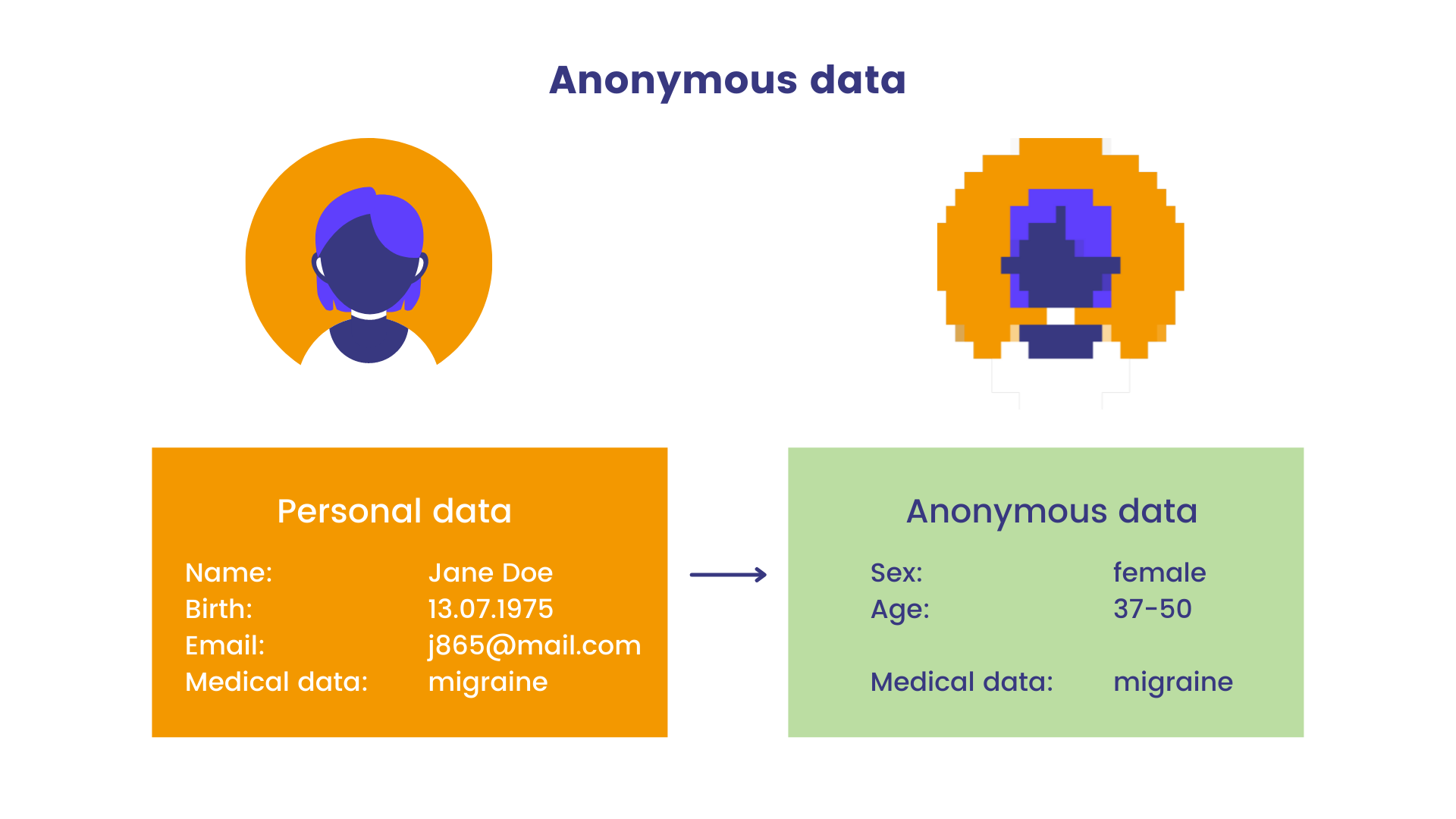
Don’t confuse anonymized data with de-identified data. The data is considered de-identified when direct or indirect identifiers linking it to a particular individual are removed, or when identification cannot be made through the use of known characteristics of that individual (deductive disclosure).
However, as pointed out by the International Association of Privacy Professionals (IAPP), de-identification doesn’t usually succeed in anonymizing data, since there are so many sources of data that still hold identifying information.
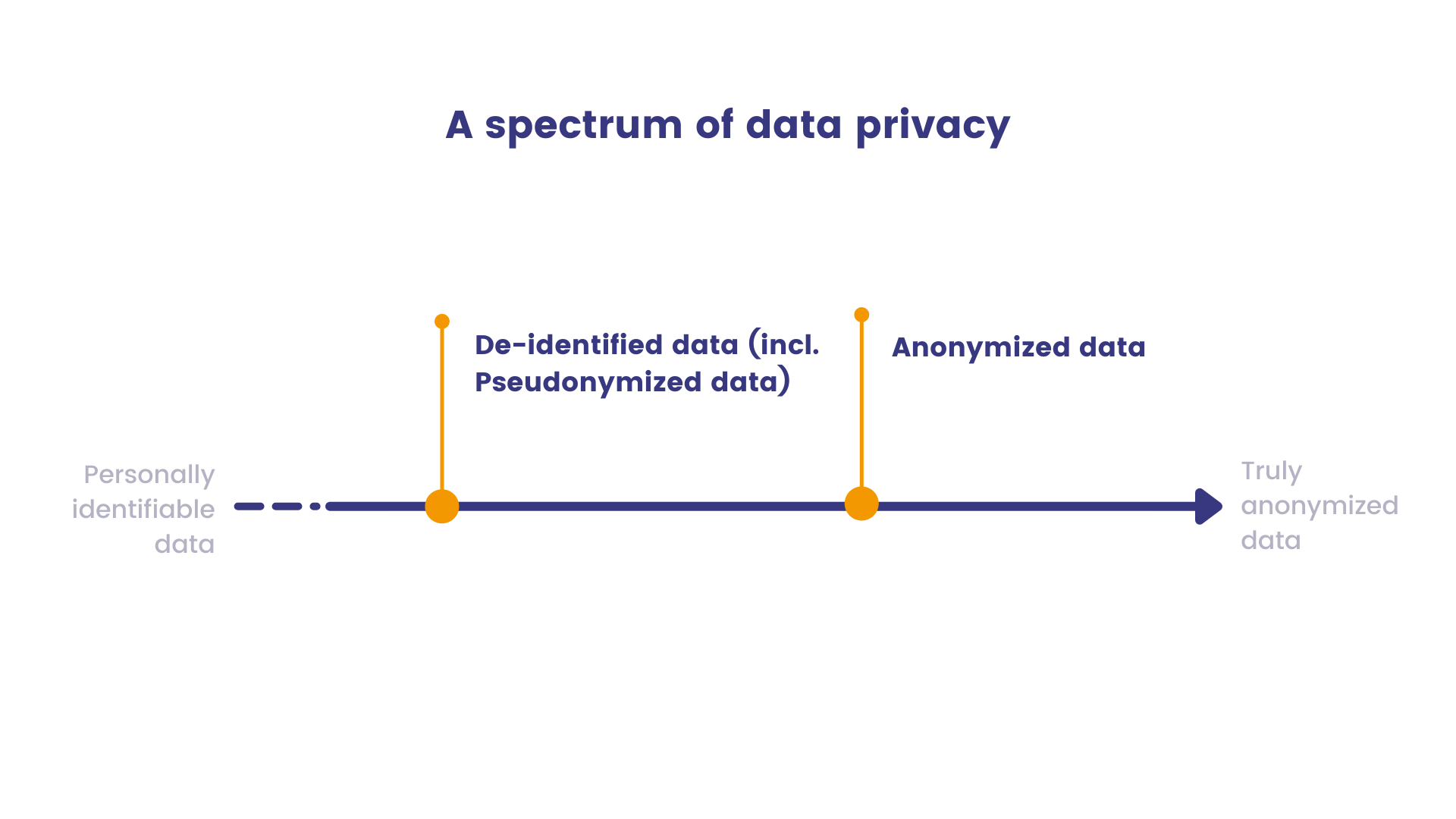
Truly anonymous data, on the other hand, doesn’t offer an opportunity for anyone, including the data handler, researcher, or a third party, to link the information to a particular individual.
Although anonymization sounds like a great plan to unlock the potential of your data, be mindful of its limitations:
A good example is the Netflix case of 2007. The streaming company published 10 million movie rankings as part of a public challenge that aimed at improving the recommendation systems. Though Netflix anonymized some of the data by removing personal details and replacing names with random numbers, two researchers de-anonymized some part of this data. They compared rankings and timestamps with publicly available information on the IMDb website, revealing personal data.
Anonymization reduces the risk of data re-identification but its effectiveness depends on other factors too. For example, what controls are put in place to prevent the anonymous dataset from being linked back to personal data. A good source of recommendations on the accountability and governance measures needed for anonymization are listed in ICO's Chapter 4.
What’s also important, data anonymization is a form of data processing. Therefore, companies must comply with the GDPR processing requirements, including consent and purpose limitation - see Article 5(1)(b). In other words, companies must have the user’s agreement to anonymize their personal data.
And lastly, companies that want to use anonymous data freely have to prove that data subjects are no longer identifiable. Those rules apply to all anonymization methods.
So far, you understand that both pseudonymization and anonymization involve hiding or data masking in some way.
There are a number of key differences between pseudonymization and anonymization. These differences are reflected in the GDPR. Pseudonymous data is still considered personal data under the GDPR while anonymized data isn’t. However, pseudonymized data also offers benefits under the GDPR, such as reduced disclosure obligations in the event of a breach, ability to conduct cross-border transfers of data (such as for EU-US data processing within one company), and lawful legitimate interest and secondary processing.

Before you decide to employ anonymous data in your analytics project, know the three risks of data re-identification.
According to Working Party Article 29, anonymous data is robust if it’s protected against the following attacks:
After reading this, you might be wondering to what extent anonymous data is really anonymous. If you’re curious, read this article.
Is there a safer method than the traditional method of data anonymization? Yes, it’s synthetic data generation.
Synthetic data is an outcome of artificial data generation. The new dataset resembles the quality of the original data and retains the statistical distribution. This means synthetic data looks like and behaves like real personal data.
If you want to keep the safe level of privacy compliance, aim at generating privacy-preserving synthetic data. Privacy-preserving synthetic data generation breaks the relationship between the original data subject and synthetic data, increasing the level of data protection.
However, machine learning models can memorize patterns of the original dataset which increases the privacy risk. So to keep the high synthetic data utility but minimize the privacy risk, you can add additional privacy layers to synthetic data – e.g., differential privacy.
For context, differential privacy (DP) is a mathematically sound definition of privacy for statistical and machine learning purposes. By looking at the output of a differentially private algorithm, one cannot determine whether a given individual's data was included in the original dataset or not. To put it another way, a differentially private algorithm is guaranteed to remain stable regardless of whether an individual joins or leaves the dataset.
DP algorithms are used to create differentially-private synthetic records based on the original distribution of data. As a result, the synthetic data benefits from the theoretical guarantees that DP provides.
These layers of protection significantly enhance the privacy of the synthetic data. However, no method can ensure perfect privacy while maintaining some utility. The GDPR requires that companies assess the residual risks of re-identification.
For example, at Statice, we developed evaluations that quantify the privacy risk of synthetic data with a set of evaluations to assess the utility and privacy of the data it produces.
---
There are benefits and downsides of using both pseudonymization and anonymization, depending on the circumstances. Anonymization can be very useful, if done properly and if the risks of re-identification through singling out, linking attacks, and inference attacks are reduced. As noted, anonymization techniques used can also degrade utility, and it is important to account for this.
On the other hand, statutory pseudonymization provides a high level of protection without degrading utility, and provides benefits under the GDPR. However, you are still covered by the regulation. In the case of anonymization, organizations need to consider the tail risk of “failed” anonymization. In the case of using statutory pseudonymization, organizations need to put in place GDPR compliance measures and account for these processes. The use of one technique or the other will depend on what the data needs to be used for.
Contact us and get feedback instantly.







