Statice's synthetic data technology is now part of Anonos Data Embassy, the award-winning data security and privacy solution.


We created this post to answer a recurring question our team encounters during conversations with customers: what are the benefits, pitfalls, and implications of building synthetic data tools versus using off-the-shelf services? This article draws on our team's five years of experience supporting enterprises with data protection to provide the best answer possible.
This article focuses only on tools for synthesizing structured data. Unstructured data may require different considerations. It should be noted that these are only suggestions based on our team's experience. Various unique factors can influence these estimates, including your use case, your industry, the size of your team, or geography.
Synthetic data is expected to completely replace real data in AI models by 2030, according to the famous estimate by Gartner. The market for synthetic data continues to grow. According to Cognilytica, its size will reach $1.15B by 2027, up from $110M in 2021.
The use of synthetic data is growing across many industries, and you may wonder how to get started.
In this article, we compare key aspects of open-source and commercial synthetic data solutions and analyze them based on a few important elements of a healthy data project. Here’s what you’ll learn:

Today, structured synthetic data generation software includes:
There are several technological approaches to generate synthetic data: VAEs (Variational Autoencoders), GANs (Generative Adversarial Networks) or other deep learning model combinations.
In terms of the functionality and services, most commercial vendors usually offer some form of privacy guarantees, meaning that the mechanisms in the synthetic data are meant to prevent the re-identification of an individual from the original data. Commercial vendors offer SaaS, professional services, support, and licensing based on monthly or annual fees. Some vendors offer free trials or plans.
It is mostly free or low-cost to use open-source solutions, so they are an attractive option for projects with a smaller budget, and you can get started with many of the tools using their communities and tutorials.
Find the list of commercial vendors here.
Let’s look at some of the open-source solutions that are available on the market.
You can also find the description of all open-source solutions in our guide or in this Github Awesome List.
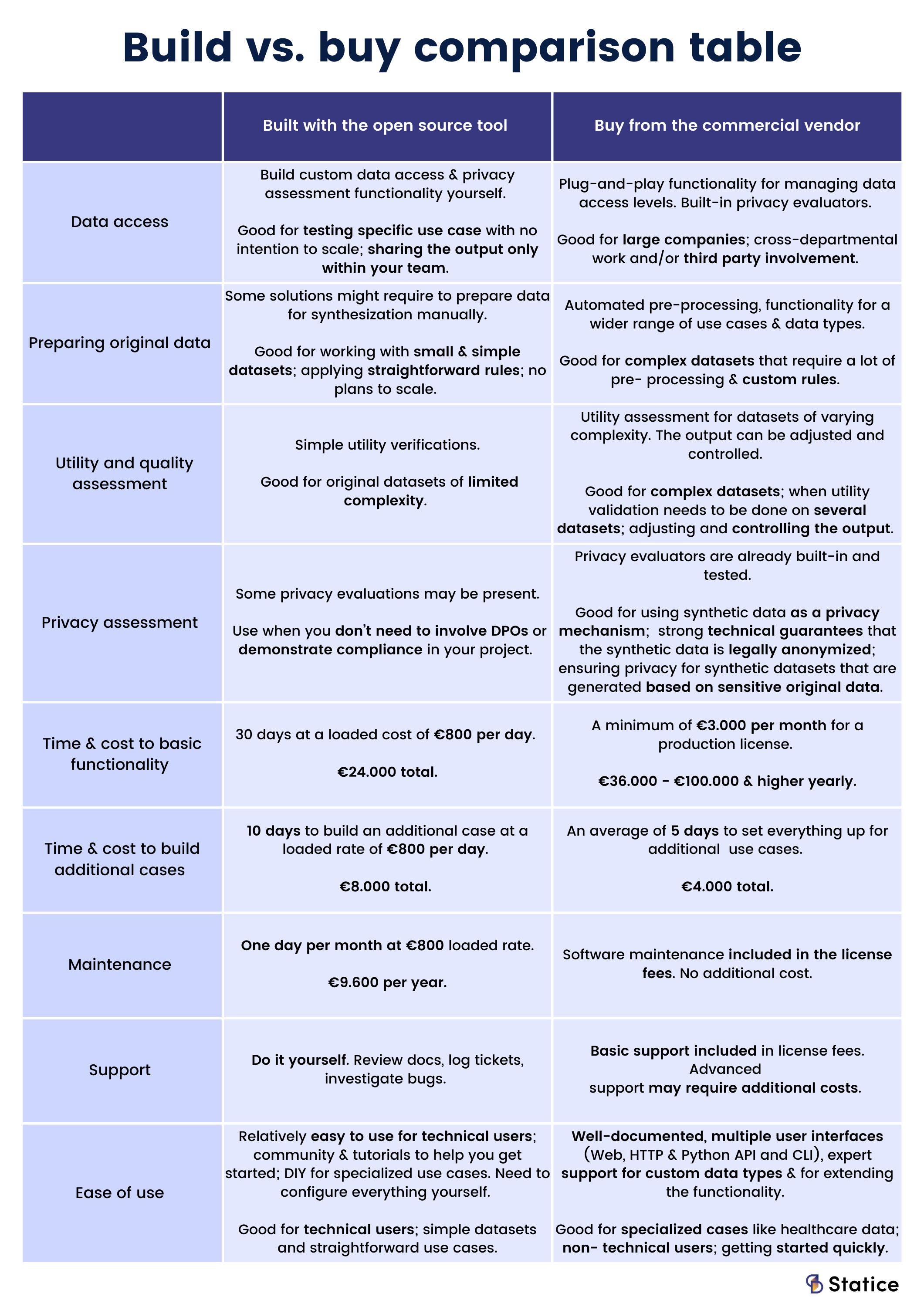
What aspects should you consider when deciding whether to build or to buy?
It is likely that your new synthetic data generator will become a part of the data lifecycle of a project or a use case you are developing. The project constraints will determine what type of tools to use. To pick the right tool, we must zoom in to examine specific steps that synthetic data projects follow. The constraints on these steps will help you determine which tool is most appropriate.

Whether you acquire data externally, gather it internally, or plan to synthesize completely new datasets, access has a big impact on everything that follows. Quickly accessing and sharing data with stakeholders is often the difference between a successful project and a failure. Consider how you will handle potential data access issues now and in the future.

Data preparation is among the most time-consuming and important phases of many data projects. To train machine learning models with synthetic test data, for example, data scientists have to prepare the original data for synthesization.
Commercial vendors, who work directly with various types of customers and use cases, tend to offer out-of-the-box functionality for a wider range of use cases and data types. Having the necessary support and expertise in a wide range of issues is a big advantage of commercial solutions.
While commercial vendors offer automated pre-processing features, some open-source tools might require you to prepare your original data for synthesization manually. The list of pre-processing tasks can grow quickly the more complex your dataset is.
Data utility refers to the analytical completeness and validity of the data. Synthetic data utility requirements are closely tied to your use case. If you plan on using your synthetic data for machine learning model training or analytics, it requires evaluating its quality and utility first. Most tools provide some utility metrics you can quickly test. Usually, commercial tools will have a larger choice of out-of-the-box evaluations.
Another crucial aspect of data access is privacy. To share synthetic data built out of data that contains personal information, you need to ensure it can withstand re-identification attacks. When companies use synthetic data as an anonymization method, the biggest question around synthetic data is how to assess the privacy risks.
Privacy is an empirical field, and without experts, it is hard to assess the risks, run privacy attacks to comply with privacy laws and get the approval of the DPO (Data Protection Officer). If you are building your own synthetic data solution based on open-source tools and need a strong privacy guarantee, we recommend involving data privacy experts to develop and verify the privacy evaluations you need.
Keep in mind that building a privacy evaluation is also time consuming. Depending on the complexity of the use case, it can take between 3 to 6 months to research, develop, test and approve synthetic data privacy with or for a DPO.
Finally, think of who needs access to a synthetic data platform in your team or company. Sometimes, it is not just data scientists but DPOs, managers or even CEOs.
For technical users, open-source tools are relatively easy to use. Some open-source solutions have Discord or Slack channels where users can ask questions and solve issues collectively. Most open source tools only are a developer toolkit or library, which isn't suited for non-technical users.
Commercial synthetic data companies typically offer ready-to-use platforms with GUIs (graphical user interfaces) and expert support. The benefit is that you don't have to be a technical user to take advantage of this, and you can support custom data types and extend functionality if needed.
Sometimes you don't have to choose between open-source and commercial vendors because you can take advantage of both with a hybrid approach.
For instance, you're happy with what you've built in-house, but your project scales. It may be necessary to perform extensive privacy evaluations in order to share your synthetic data. In this case, you can perform privacy assessments using scientifically proven commercial vendor functionality.
You can also use vendor expertise and services when you need expert help building your own tool.

The cost of setting up and running your synthetic data project varies greatly. Creating a unit devoted to synthetic data can be very expensive. On the other hand, if your project is small, free open-source software like SDV may suffice.
Let's consider the following example to estimate the potential budget needs of a synthetic data project. Suppose you need to run a small synthetic data project without the need of extensive (or any) privacy evaluations and DPO approvals. You plan to use it within your data science team and no external stakeholders will be involved.
Let’s take a look at the approximate costs of such a project.
Commercial vendors and open-source tools both have amazing features. The specifics and goals of your data project will determine which category suits you best. When making your decision, consider your project's use case, its complexity, your stakeholders' needs, maintenance budget, and, of course, the security of your sensitive data.
Contact us and get feedback instantly.







