Statice's synthetic data technology is now part of Anonos Data Embassy, the award-winning data security and privacy solution.


Our team worked hard over the summer to bring new capabilities to the Statice Platform and SDK. This month, we are releasing new features, including:
The new data simulation functionality lets you generate new tabular datasets from scratch. To obtain realistic-looking data in minutes, you have to input the types of columns (emails, names, IBAN, etc.) and the size of the dataset you want to create. This feature is perfect when you lack test or real data or your original dataset is too small.
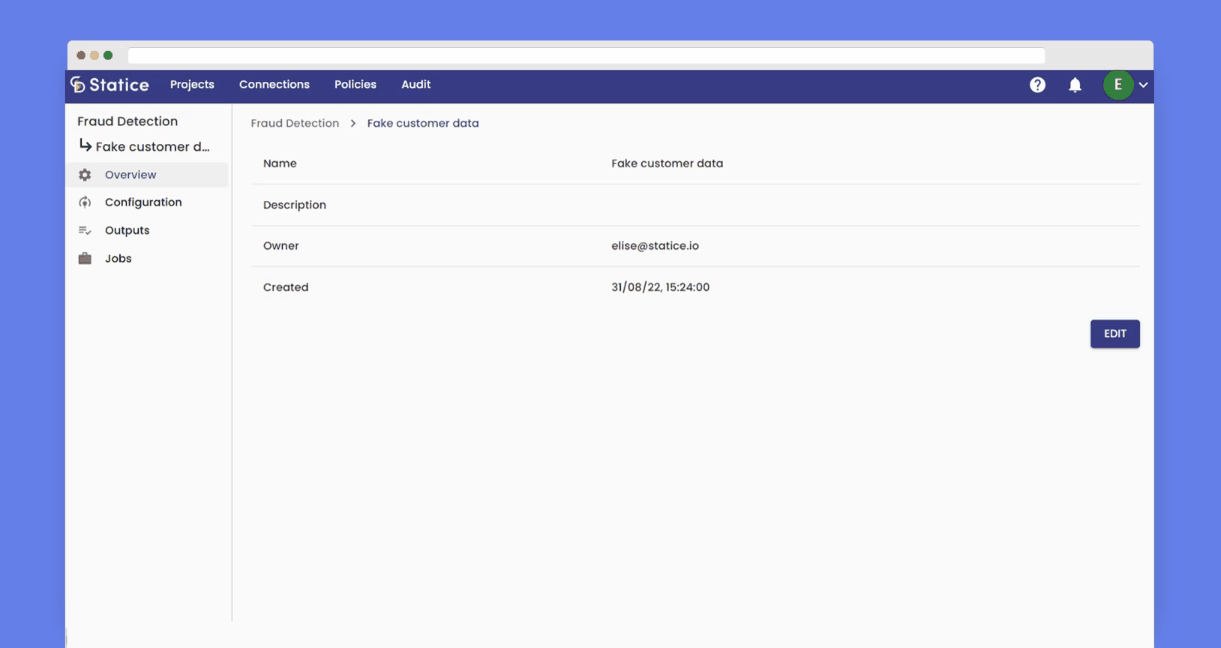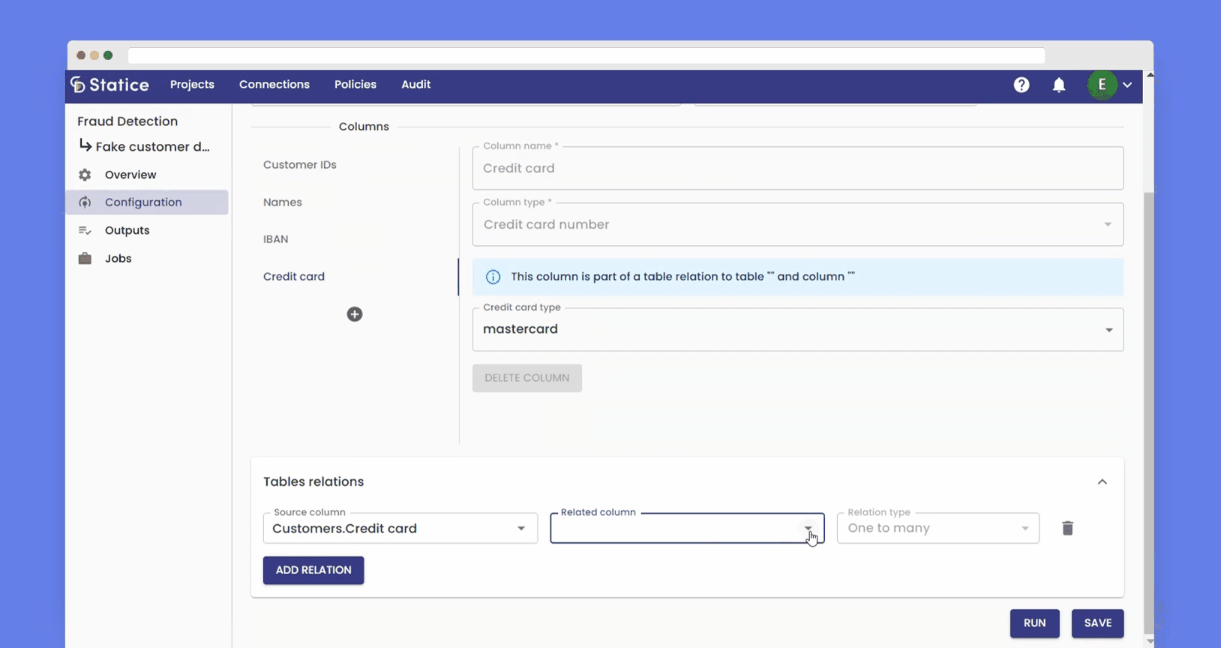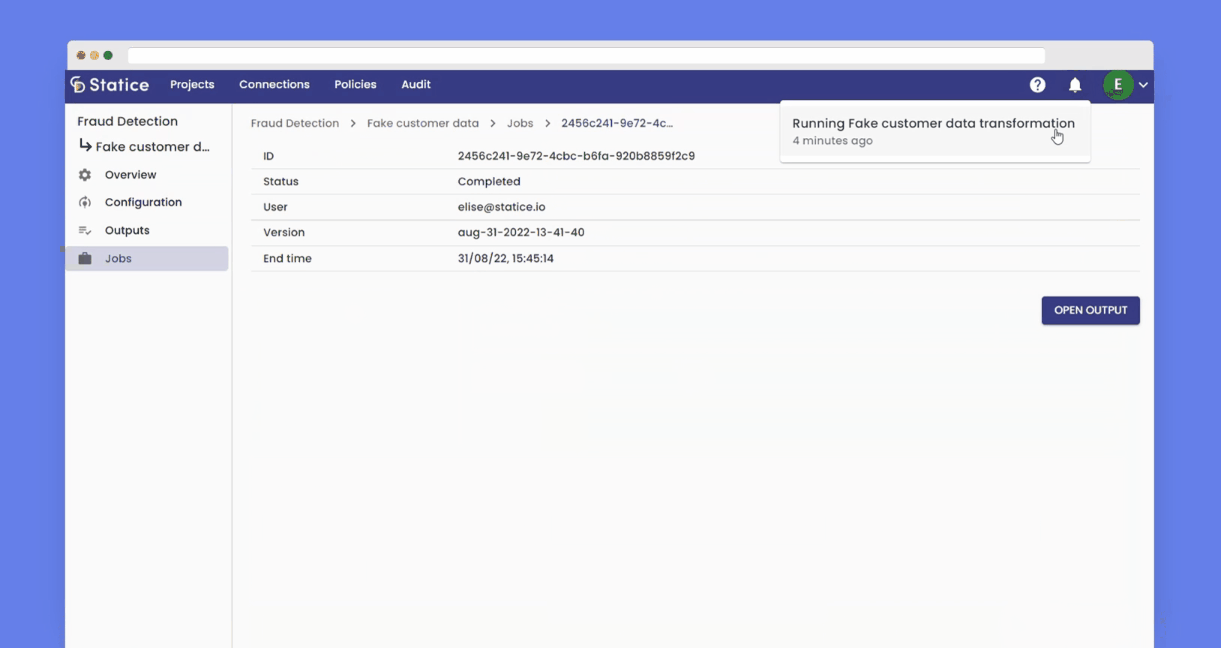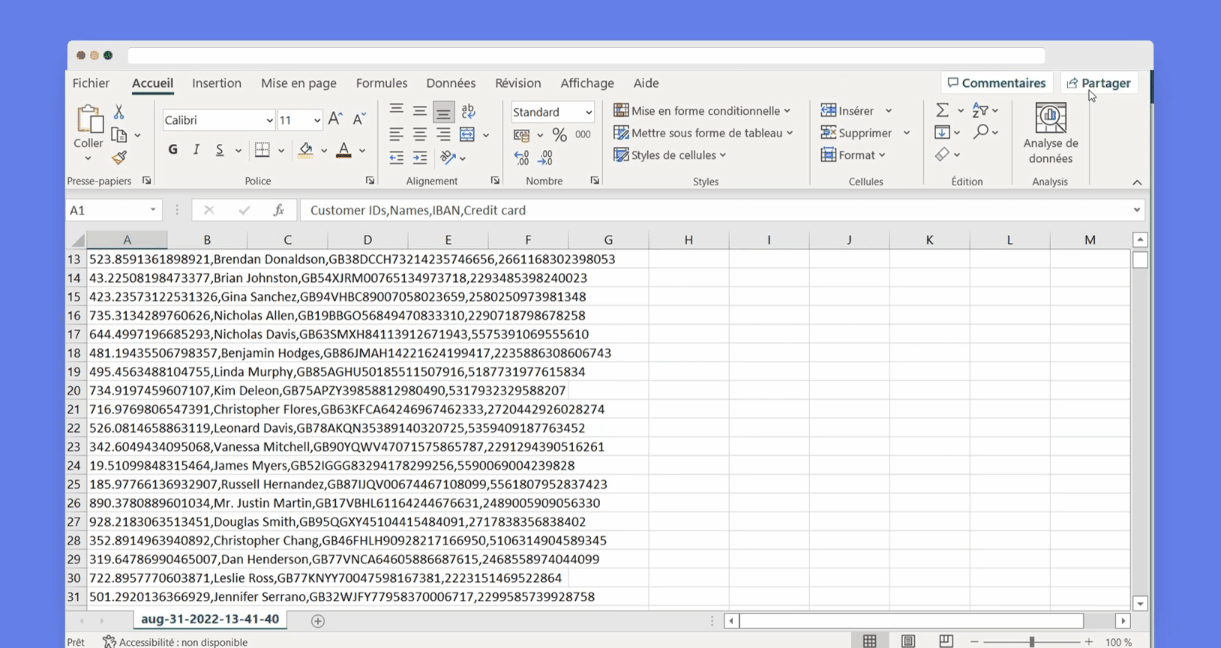
You can generate, among other things, columns of fake addresses, bank information, credit cards, dates, identities, and contact details. You can choose several regions and languages to obtain localized datasets. You simulate as many or as few tables and rows as you need. You can define distribution rules so your new data matches specific statistical properties.
We added support for PDF documents in our sanitization feature to better answer use-case needs and the data reality of many organizations.
You can now process PDF files and use the sanitization operators (masking, redacting, replacing) in these documents. Detecting and protecting your PII has never been so easy! This functionality also has multi-language support.

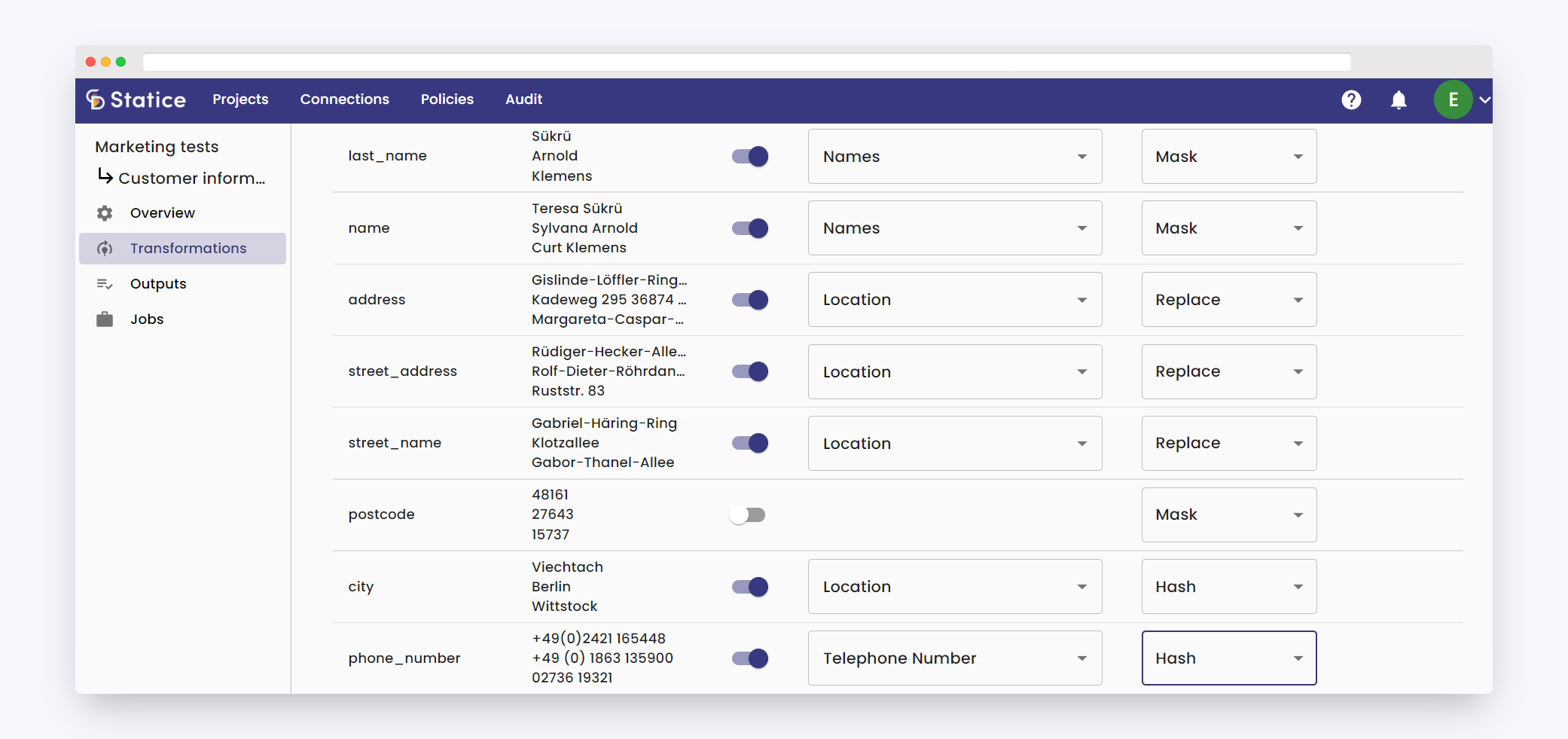
Chances are, if you are working with German or French data, that Personally Identifiable Information (PII) is not so easily automatically detected.
So we added support of multiple languages to our data sanitization capability. You can now automatically detect and protect names, locations, or any PII in your datasets regardless of the language: mask, redact, or hash sensitive information in German, French, or the language of your choice.
You can now configure a connection to PostgreSQL, MySQL, MariaDB, or Microsoft SQL Server in a few clicks. Connect the data storage of your choice to easily load data into the platform and save anonymized or sanitized datasets.


We’ve made our solution deployment more flexible with the possibility to deploy using Docker Compose.
You can install our solution on virtual machines or bare metal using this deployment method. This option adds to the Kubernetes or self-deployment methods already available.
We shipped a new major version of our SDK which improves the performance and adds more privacy features. It comes with revised APIs enriched from months of customer feedback and collaboration. This version offers more transparency and control over the synthetic data generation process. Once you obtain synthetic data, you can more easily audit how the synthesizer generated it.
On the privacy side, the SDK now allows the suppression of rare categories in categorical columns to improve the protection of outliers during synthesization. It reinforces the protection against singling out and membership attacks, improving the overall privacy of the synthetic data.

Contact us and get feedback instantly.







